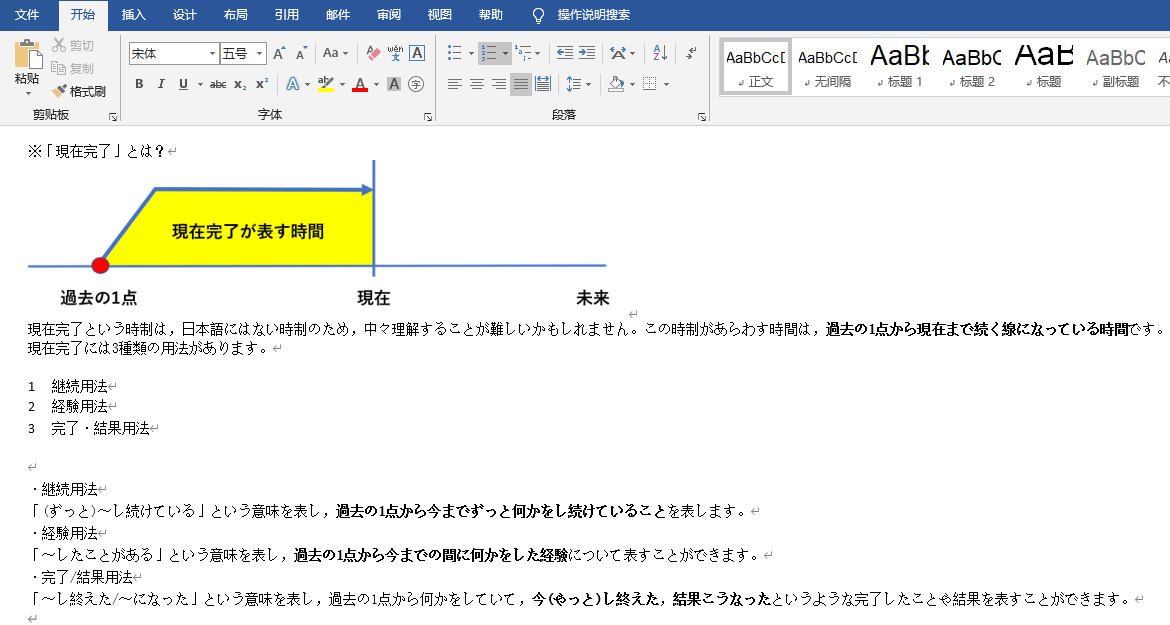
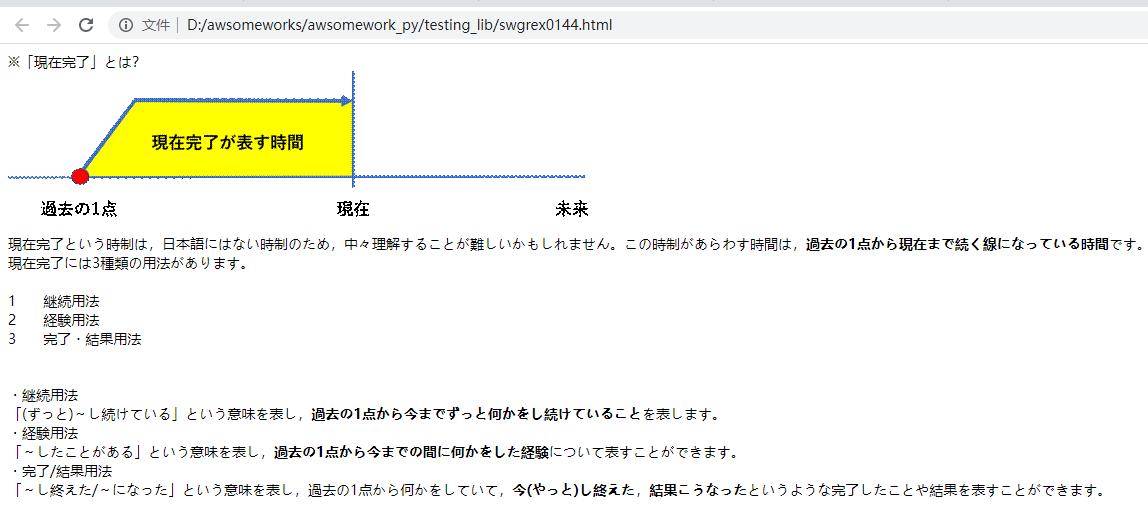
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
window = tk.Tk()
window.title("Word转Html工具")
window.geometry('600x300')
# 设置输入 1 2
path_var = tk.StringVar()
entry = tk.Entry(window, textvariable=path_var, width=60)
entry.place(x=20, y=10, anchor='nw')
path_var1 = tk.StringVar()
entry1 = tk.Entry(window, textvariable=path_var1, width=60)
entry1.place(x=20, y=60, anchor='nw')
def choose_file_click():
"""
选择文件事件定义
"""
# 设置可以选择的文件类型,不属于这个类型的,无法被选中
file_types = [("word文件", "*.docx")]
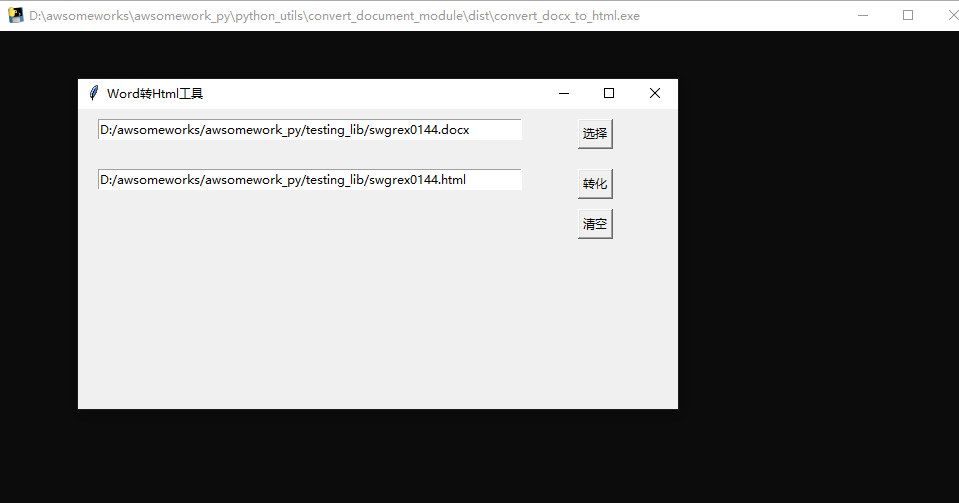
file_name = filedialog.askopenfilename(title='选择单个文件',
filetypes=file_types,
initialdir='./') # 打开当前程序工作目录
path_var.set(file_name)
def convert_file_click():
"""
word转html事件定义
"""
src_file_path = path_var.get()
convert_fil_path = convert(src_file_path)
path_var1.set(convert_fil_path)
def clear_clik():
"""
清空所有事件定义
"""
path_var.set("")
path_var1.set("")
choose_btn = tk.Button(window, text='选择', command=choose_file_click)
choose_btn.place(x=450, y=10, anchor='nw')
convert_btn = tk.Button(window, text='转化', command=convert_file_click)
convert_btn.place(x=450, y=60, anchor='nw')
clear_btn = tk.Button(window, text='清空', command=clear_clik)
clear_btn.place(x=450, y=100, anchor='nw')
window.mainloop()
|